MultiVelo Demo
We will use the embryonic E18 mouse brain from 10X Multiome as an example.
CellRanger output files can be downloaded from 10X website. Crucially, the filtered feature barcode matrix folder, ATAC peak annotations TSV, and the feature linkage BEDPE file in the secondary analysis outputs folder will be needed in this demo.
Quantified unspliced and spliced counts from Velocyto can be downloaded from MultiVelo GitHub page.
We provide the cell annotations for this dataset in “cell_annotations.tsv” on the GitHub page. (To download from GitHub, click on the file, then click “Raw” on the top right corner. If it opens in your browser, you can download the page as a text file.)
Weighted nearest neighbors from Seurat can be downloaded from GitHub folder “seurat_wnn”, which contains a zip file of three files: “nn_cells.txt”, “nn_dist.txt”, and “nn_idx.txt”. Please unzip the archive after downloading. The R script used to generate such files can also be found in the same folder.
.
|-- MultiVelo_Demo.ipynb
|-- cell_annotations.tsv
|-- outs
| |-- analysis
| | `-- feature_linkage
| | `-- feature_linkage.bedpe
| |-- filtered_feature_bc_matrix
| | |-- barcodes.tsv.gz
| | |-- features.tsv.gz
| | `-- matrix.mtx.gz
| `-- peak_annotation.tsv
|-- seurat_wnn
| |-- nn_cells.txt
| |-- nn_dist.txt
| `-- nn_idx.txt
`-- velocyto
`-- 10X_multiome_mouse_brain.loom
[1]:
import os
import scipy
import numpy as np
import pandas as pd
import scanpy as sc
import scvelo as scv
import multivelo as mv
import matplotlib.pyplot as plt
[2]:
scv.settings.verbosity = 3
scv.settings.presenter_view = True
scv.set_figure_params('scvelo')
pd.set_option('display.max_columns', 100)
pd.set_option('display.max_rows', 200)
np.set_printoptions(suppress=True)
Reading in unspliced and spliced counts
[3]:
adata_rna = scv.read("velocyto/10X_multiome_mouse_brain.loom", cache=True)
adata_rna.obs_names = [x.split(':')[1][:-1] + '-1' for x in adata_rna.obs_names]
adata_rna.var_names_make_unique()
Variable names are not unique. To make them unique, call `.var_names_make_unique`.
[4]:
sc.pp.filter_cells(adata_rna, min_counts=1000)
sc.pp.filter_cells(adata_rna, max_counts=20000)
[5]:
# Top 1000 variable genes are used for downstream analyses.
scv.pp.filter_and_normalize(adata_rna, min_shared_counts=10, n_top_genes=1000)
Filtered out 21580 genes that are detected 10 counts (shared).
Normalized count data: X, spliced, unspliced.
Extracted 1000 highly variable genes.
[6]:
# Load cell annotations
cell_annot = pd.read_csv('cell_annotations.tsv', sep='\t', index_col=0)
[7]:
adata_rna = adata_rna[cell_annot.index,:]
adata_rna.obs['celltype'] = cell_annot['celltype']
Trying to set attribute `.obs` of view, copying.
[8]:
# We subset for lineages towards neurons and astrocytes.
adata_rna = adata_rna[adata_rna.obs['celltype'].isin(['RG, Astro, OPC',
'IPC',
'V-SVZ',
'Upper Layer',
'Deeper Layer',
'Ependymal cells',
'Subplate'])]
adata_rna
[8]:
View of AnnData object with n_obs × n_vars = 3653 × 1000
obs: 'n_counts', 'initial_size_spliced', 'initial_size_unspliced', 'initial_size', 'celltype'
var: 'Accession', 'Chromosome', 'End', 'Start', 'Strand', 'gene_count_corr', 'means', 'dispersions', 'dispersions_norm', 'highly_variable'
layers: 'ambiguous', 'matrix', 'spliced', 'unspliced'
Preprocessing the ATAC counts
[9]:
adata_atac = sc.read_10x_mtx('outs/filtered_feature_bc_matrix/', var_names='gene_symbols', cache=True, gex_only=False)
adata_atac = adata_atac[:,adata_atac.var['feature_types'] == "Peaks"]
[10]:
# We aggregate peaks around each gene as well as those that have high correlations with promoter peak or gene expression.
# Peak annotation contains the metadata for all peaks.
# Feature linkage contains pairs of correlated genomic features.
adata_atac = mv.aggregate_peaks_10x(adata_atac,
'outs/peak_annotation.tsv',
'outs/analysis/feature_linkage/feature_linkage.bedpe',
verbose=True)
CellRanger ARC identified as 1.0.0
Found 19006 genes with promoter peaks
[11]:
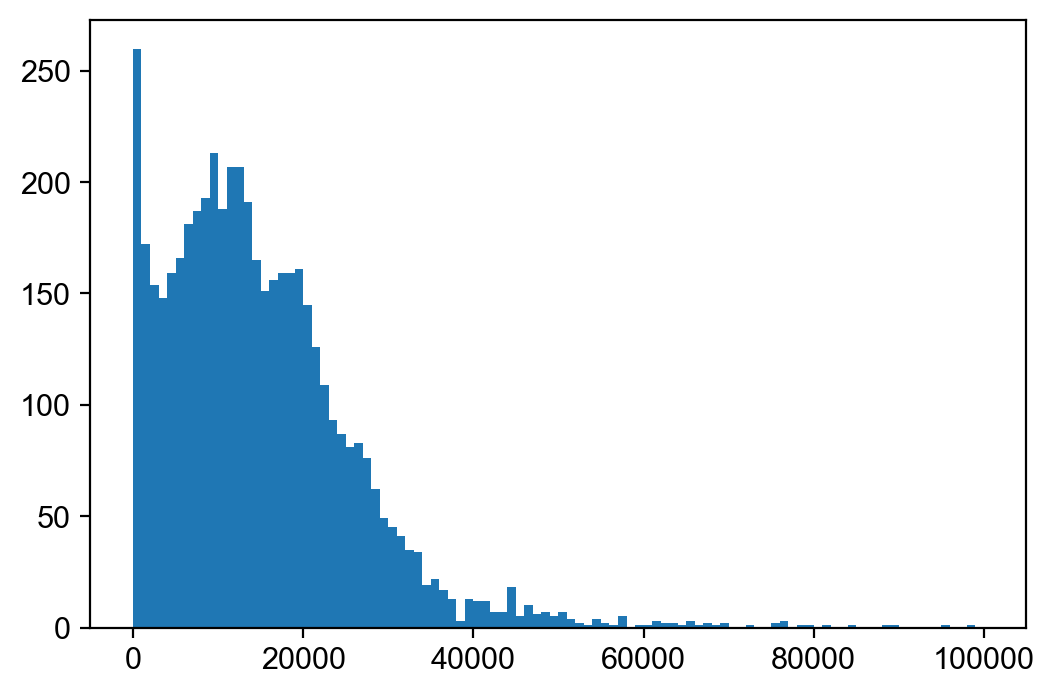
# Let's examine the total count distribution and remove outliers.
plt.hist(adata_atac.X.sum(1), bins=100, range=(0, 100000));
[12]:
sc.pp.filter_cells(adata_atac, min_counts=2000)
sc.pp.filter_cells(adata_atac, max_counts=60000)
Trying to set attribute `.obs` of view, copying.
[13]:
# We normalize aggregated peaks with TF-IDF.
mv.tfidf_norm(adata_atac)
Finding shared barcodes and features between RNA and ATAC
[14]:
shared_cells = pd.Index(np.intersect1d(adata_rna.obs_names, adata_atac.obs_names))
shared_genes = pd.Index(np.intersect1d(adata_rna.var_names, adata_atac.var_names))
len(shared_cells), len(shared_genes)
[14]:
(3365, 936)
[15]:
# We reload in the raw data and continue with a subset of cells.
adata_rna = scv.read("velocyto/10X_multiome_mouse_brain.loom", cache=True)
adata_rna.obs_names = [x.split(':')[1][:-1] + '-1' for x in adata_rna.obs_names]
adata_rna.var_names_make_unique()
Variable names are not unique. To make them unique, call `.var_names_make_unique`.
[16]:
adata_rna = adata_rna[shared_cells, shared_genes]
adata_atac = adata_atac[shared_cells, shared_genes]
[17]:
scv.pp.normalize_per_cell(adata_rna)
scv.pp.log1p(adata_rna)
scv.pp.moments(adata_rna, n_pcs=30, n_neighbors=50)
Normalized count data: X, spliced, unspliced.
computing neighbors
finished (0:00:01) --> added
'distances' and 'connectivities', weighted adjacency matrices (adata.obsp)
computing moments based on connectivities
finished (0:00:00) --> added
'Ms' and 'Mu', moments of un/spliced abundances (adata.layers)
[18]:
adata_rna.obs['celltype'] = cell_annot.loc[adata_rna.obs_names, 'celltype']
adata_rna.obs['celltype'] = adata_rna.obs['celltype'].astype('category')
[19]:
# Reorder the categories for color consistency with the manuscript.
all_clusters = ['Upper Layer',
'Deeper Layer',
'V-SVZ',
'RG, Astro, OPC',
'Ependymal cells',
'IPC',
'Subplate']
adata_rna.obs['celltype'] = adata_rna.obs['celltype'].cat.reorder_categories(all_clusters)
[20]:
scv.tl.umap(adata_rna)
scv.pl.umap(adata_rna, color='celltype')

Smoothing gene aggregagted peaks by neighbors
[21]:
# Write out filtered cells and prepare to run Seurat WNN --> R script can be found on Github.
adata_rna.obs_names.to_frame().to_csv('filtered_cells.txt', header=False, index=False)
[22]:
# Read in Seurat WNN neighbors.
nn_idx = np.loadtxt("seurat_wnn/nn_idx.txt", delimiter=',')
nn_dist = np.loadtxt("seurat_wnn/nn_dist.txt", delimiter=',')
nn_cells = pd.Index(pd.read_csv("seurat_wnn/nn_cells.txt", header=None)[0])
# Make sure cell names match.
np.all(nn_cells == adata_atac.obs_names)
[22]:
True
[23]:
mv.knn_smooth_chrom(adata_atac, nn_idx, nn_dist)
[24]:
adata_atac
[24]:
AnnData object with n_obs × n_vars = 3365 × 936
obs: 'n_counts'
layers: 'Mc'
obsp: 'connectivities'
Running multi-omic dynamical model
MultiVelo incorporates chromatin accessibility information into RNA velocity and achieves better lineage predictions.
The detailed argument list can be shown with “help(mv.recover_dynamics_chrom)”.
[25]:
# This will take a while. Parallelization is high recommended.
adata_result = mv.recover_dynamics_chrom(adata_rna,
adata_atac,
max_iter=5,
init_mode="invert",
verbose=False,
parallel=True,
save_plot=False,
rna_only=False,
fit=True,
n_anchors=500,
extra_color_key='celltype'
)
[26]:
# Save the result for use later on
adata_result.write("multivelo_result.h5ad")
... storing 'fit_direction' as categorical
[27]:
adata_result = sc.read_h5ad("multivelo_result.h5ad")
[28]:
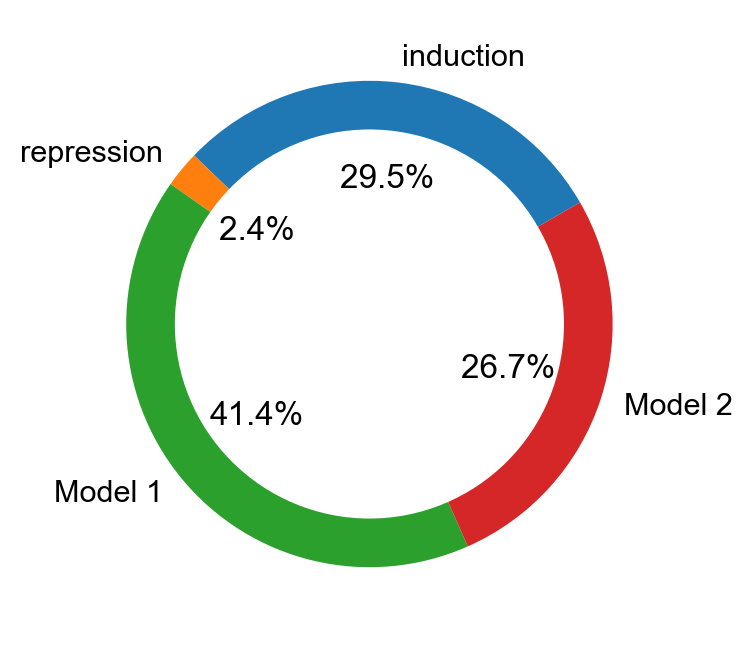
mv.pie_summary(adata_result)
[29]:
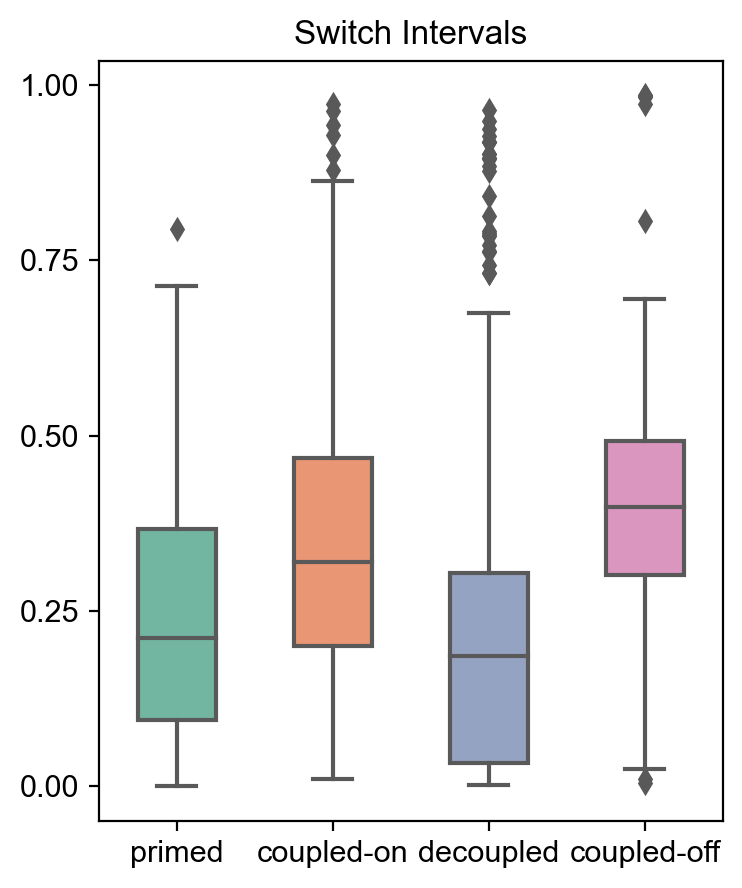
mv.switch_time_summary(adata_result)
[30]:
mv.likelihood_plot(adata_result)
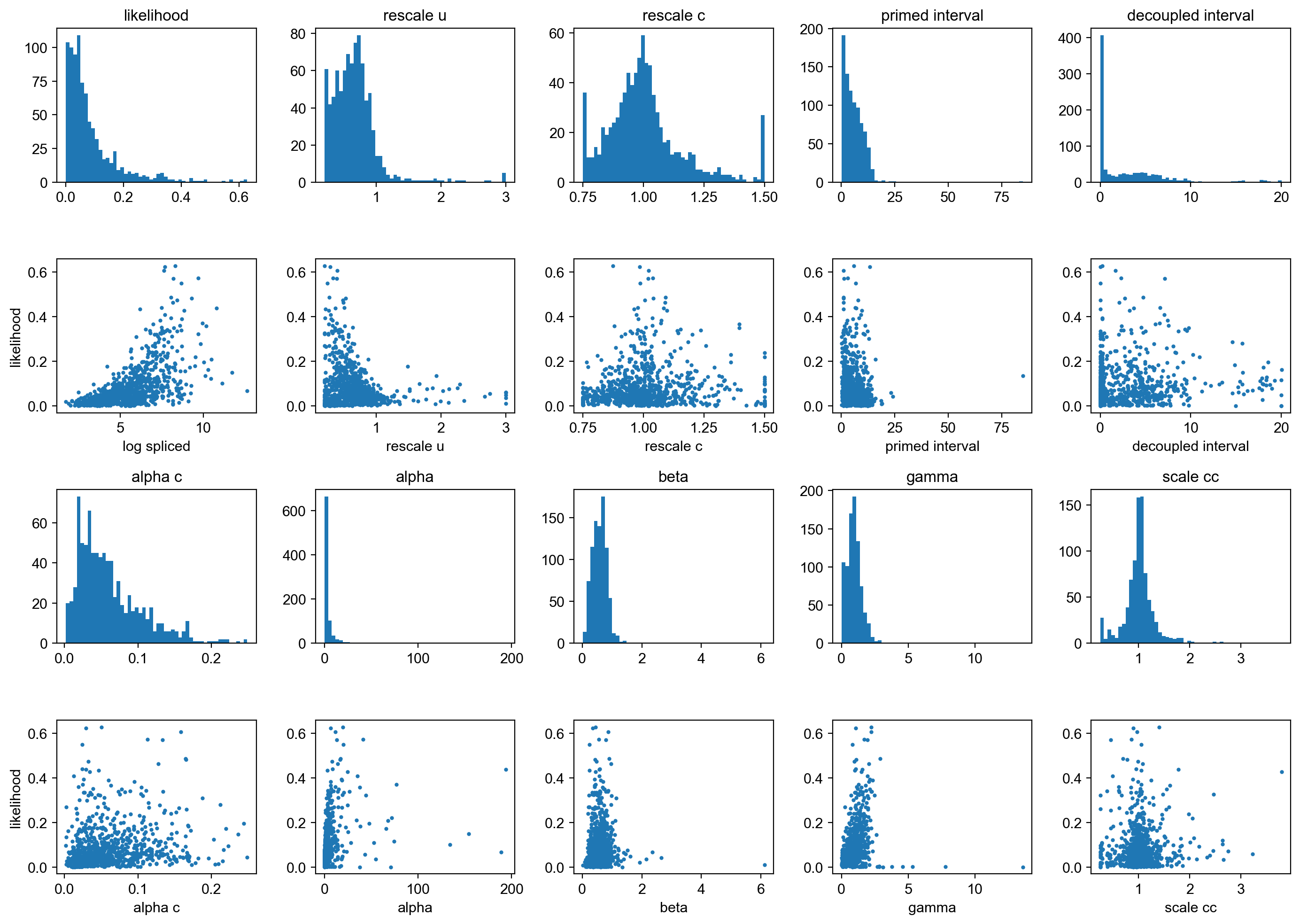
By default, the velocity genes used for velocity graph is determined as those whose likelihoods are above 0.05. They can be reset with “mv.set_velocity_genes” function upon examining the distributions of variables above if needed.
Computing velocity stream and latent time
[31]:
mv.velocity_graph(adata_result)
mv.latent_time(adata_result)
computing velocity graph (using 1/12 cores)
finished (0:00:04) --> added
'velo_s_norm_graph', sparse matrix with cosine correlations (adata.uns)
computing terminal states
identified 1 region of root cells and 1 region of end points .
finished (0:00:00) --> added
'root_cells', root cells of Markov diffusion process (adata.obs)
'end_points', end points of Markov diffusion process (adata.obs)
computing latent time using root_cells as prior
finished (0:00:00) --> added
'latent_time', shared time (adata.obs)
[32]:
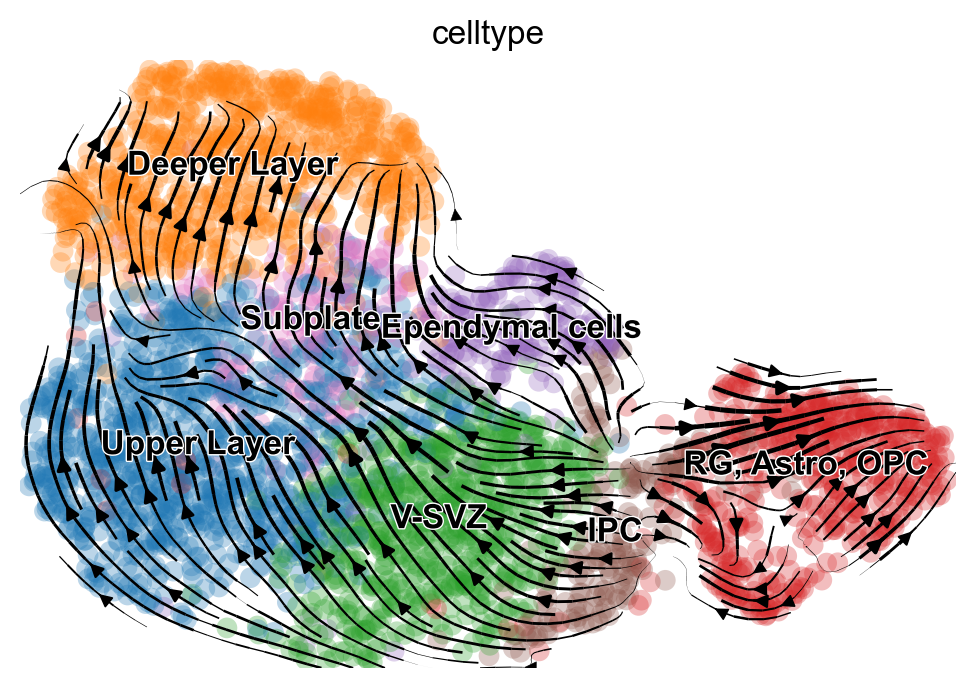
mv.velocity_embedding_stream(adata_result, basis='umap', color='celltype')
computing velocity embedding
finished (0:00:00) --> added
'velo_s_norm_umap', embedded velocity vectors (adata.obsm)
[33]:
scv.pl.scatter(adata_result, color='latent_time', color_map='gnuplot', size=80)
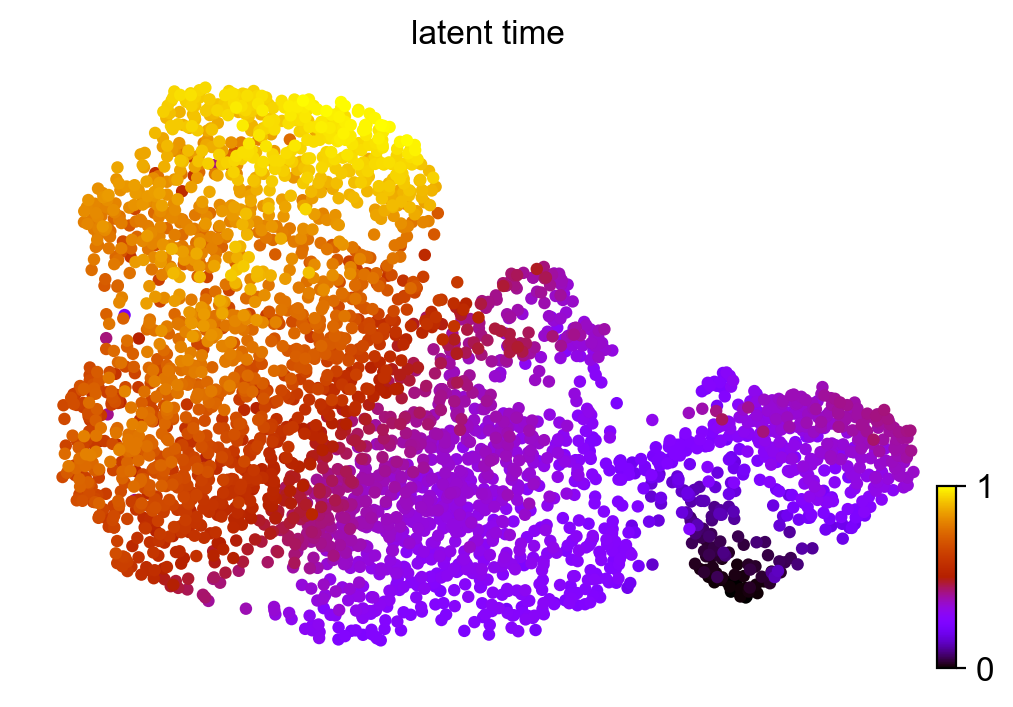
Let’s examine some example genes.
[34]:
gene_list = ['Grin2b', 'Tle4', 'Robo2', 'Satb2', 'Gria2']
We can plot accessbility and expression against gene time.
[35]:
# Accessibility/expression by gene time, colored by the four potential states.
# The solid black curve indicates anchors.
mv.dynamic_plot(adata_result, gene_list, color_by='state', axis_on=False, frame_on=False)
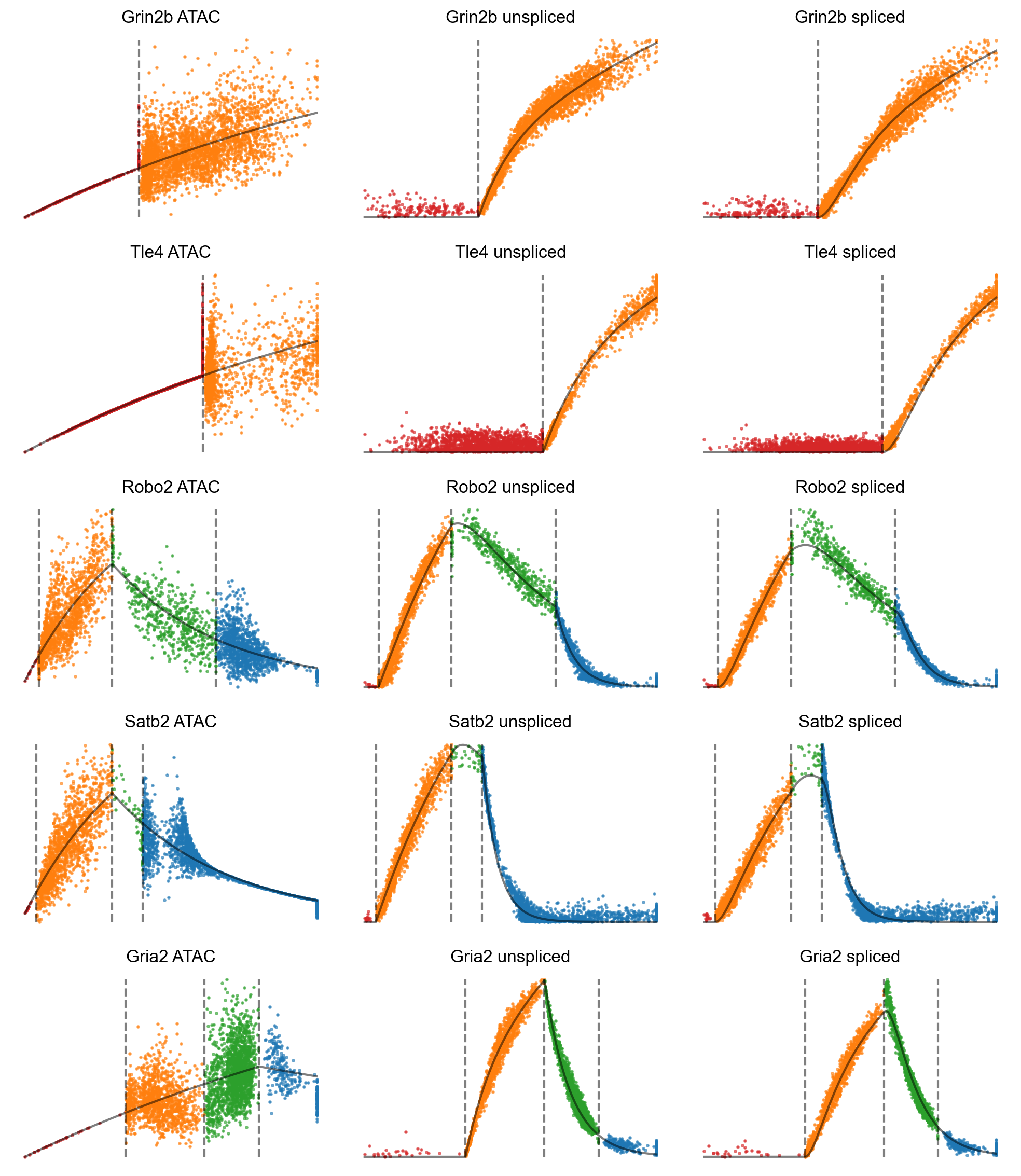
We can plot velocity against gene time.
[36]:
# Velocity by gene time, colored by the four potential states.
# The solid black curve indicates anchors.
mv.dynamic_plot(adata_result, gene_list, color_by='state', by='velocity', axis_on=False, frame_on=False)
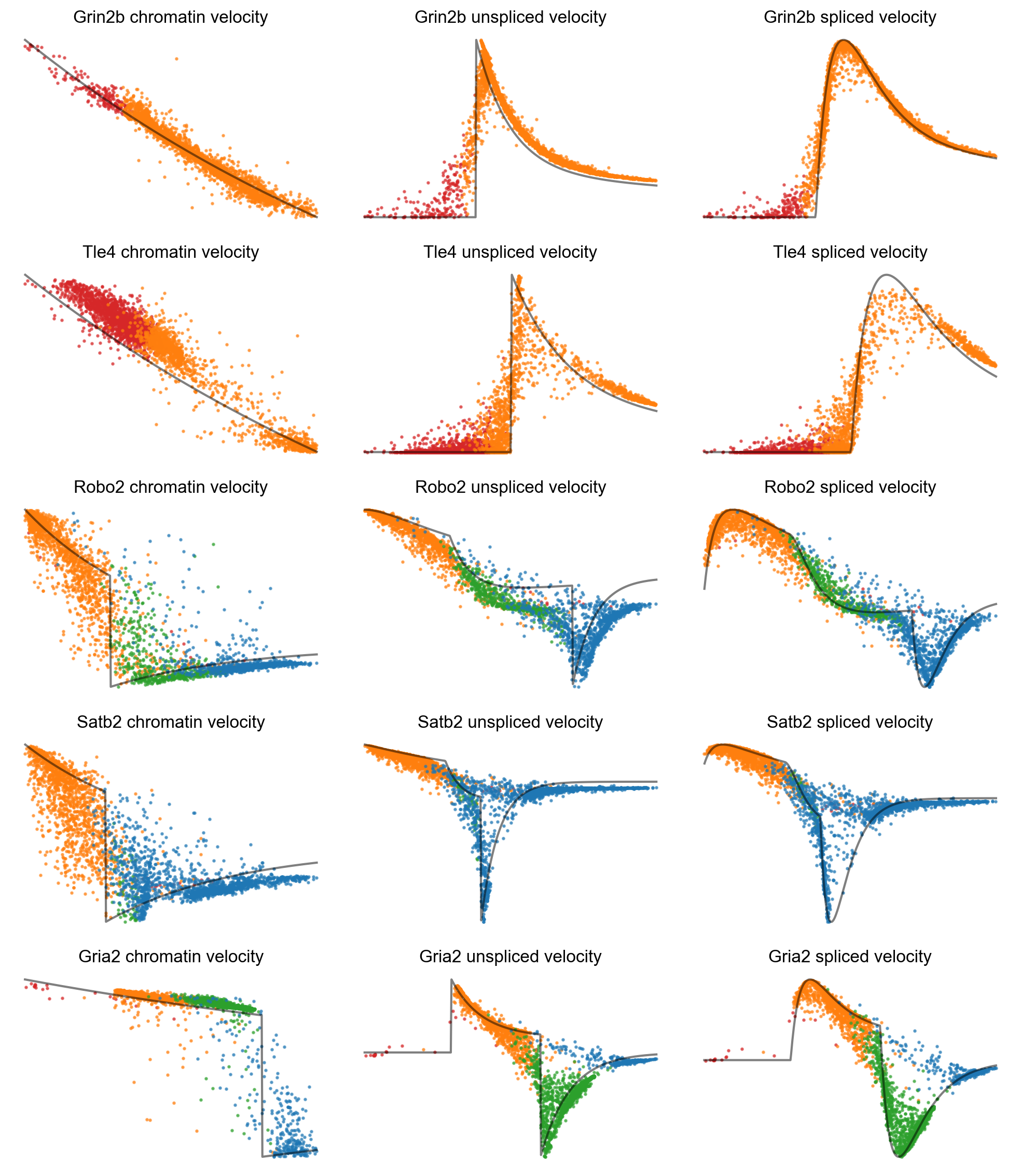
We can examine accessibility and expression against globally shared latent time.
[37]:
# Accessibility/expression by global latent time, colored by cell type assignments.
# The solid black curve indicates the mean.
mv.dynamic_plot(adata_result, gene_list, color_by='celltype', gene_time=False, axis_on=False, frame_on=False)
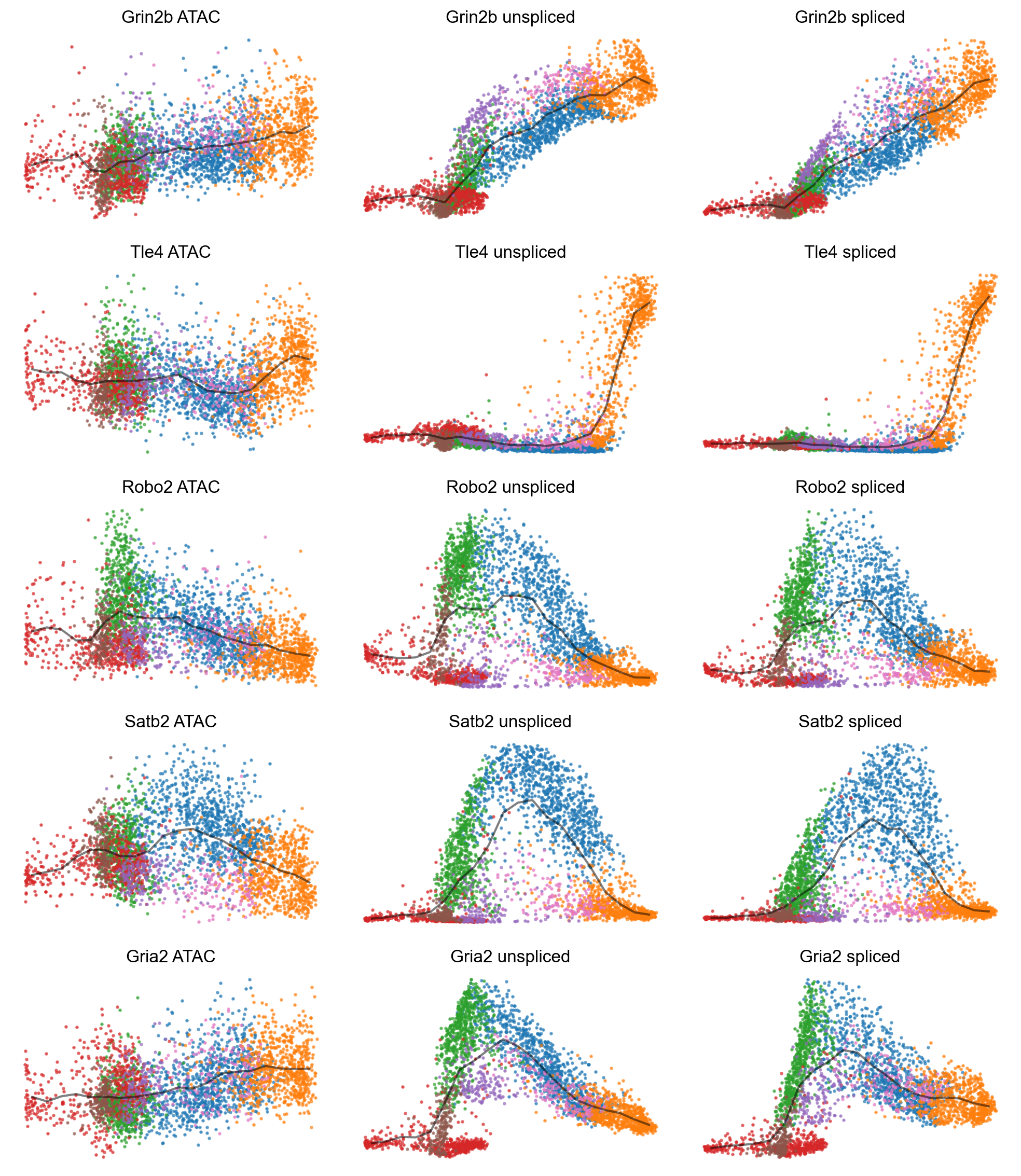
Phase portraits on the unspliced-spliced, chromatin-unspliced, or 3-dimensional planes can be plotted.
[38]:
# Unspliced-spliced phase portraits, colored by celltype.
mv.scatter_plot(adata_result, gene_list, color_by='celltype', by='us', axis_on=False, frame_on=False)

[39]:
# Unspliced-spliced phase portraits, colored by log chromatin accessibility.
# title_more_info shows more information in each subplot title: model, direction, and likelihood.
mv.scatter_plot(adata_result, gene_list, color_by='c', by='us', cmap='coolwarm', title_more_info=True, axis_on=False, frame_on=False)

[40]:
# Chromatin-unspliced phase portraits, colored by celltype.
mv.scatter_plot(adata_result, gene_list, color_by='celltype', by='cu', axis_on=False, frame_on=False)

[41]:
# 3D phase portraits, colored by celltype.
mv.scatter_plot(adata_result, gene_list, color_by='celltype', by='cus', axis_on=False, downsample=2)

We can also add velocity arrows to phase portraits to show the predicted directions.
[42]:
mv.scatter_plot(adata_result, gene_list, color_by='celltype', by='us', axis_on=False, frame_on=False, downsample=2, velocity_arrows=True)

[43]:
mv.scatter_plot(adata_result, gene_list, color_by='celltype', by='cu', axis_on=False, frame_on=False, downsample=2, velocity_arrows=True)

[44]:
mv.scatter_plot(adata_result, gene_list, color_by='celltype', by='cus', downsample=3, velocity_arrows=True)
